KeyAssort — как составить семантическое ядро и на его основе создать структуру сайта

Хочу сделать очередной заход на тему «сбора семядра». Сначала будет немного лирики, как полагается, а потом много практики, может быть и несколько неуклюжей в моем исполнении. Итак, лирика. Ходить с завязанными глазами в поисках удачи мне надоело уже через год, после начала ведения этого блога. Да, были «удачные попадания» (интуитивное угадывание часто задаваемых поисковикам запросов) и был определенный трафик с поисковиков, но хотелось каждый раз бить в цель (по крайней мере, ее видеть).
По сути ж ведь нет ничего зазорного в том, чтобы заранее понять, в какие чудесные слова облекают свои хотелки те, кому будут адресованы будущие публикации. Учтя это (собрав семантику под статью), мы повышаем шансы на успех (покорение Топа по этим фразам — см. словарь SEO-балбеса). По этому поводу была написана статья про работу с Вордстатом и этап сбора семядра.
Потом захотелось большего — автоматизации процесса сбора запросов и отсева «пустышек». По этой причине появился опыт работы с Кейколлектором (и его неблагозвучным младшим братом) и очередная статья на тему автоматизации процесса подбора поисковых запросов. Все было здорово и даже просто замечательно, пока я не понял, что есть один таки очень важный момент, оставшийся по сути за кадром — раскидывание запросов по статьям.
Писать отдельную статью под отдельный запрос оправдано либо в высококонкурентных тематиках, либо в сильно доходных. Для инфосайтов же — это полный бред, а посему приходится запросы объединять на одной странице. Как? Интуитивно, т.е. опять же вслепую. А ведь далеко не все запросы уживаются на одной странице и имеют хотя бы гипотетический шанс выйти в Топ.
Собственно, сегодня как раз и пойдет речь об автоматической кластеризации семантического ядра посредством KeyAssort (разбивке запросов по страницам, а для новых сайтов еще и построение на их основе структуры, т.е. разделов, категорий). Ну, и сам процесс сбора запросов мы еще раз пройдем на всякий пожарный (в том числе и с новыми инструментами).
Какой из этапов сбора семантического ядра самый важный?
Сам по себе сбор запросов (основы семантического ядра) для будущего или уже существующего сайта является процессом довольно таки интересным (кому как, конечно же) и реализован может быть несколькими способами, результаты которых можно будет потом объединить в один большой список (почистив дубли, удалив пустышки по стоп словам).
Например, можно вручную начать терзать Вордстат, а в добавок к этому подключить Кейколлектор (или его неблагозвучную бесплатную версию). Однако, это все здорово, когда вы с тематикой более-менее знакомы и знаете ключи, на которые можно опереться (собирая их производные и схожие запросы из правой колонки Вордстата).
В противном же случае (да, и в любом случае это не помешает) начать можно будет с инструментов «грубого помола». Например, Serpstat (в девичестве Prodvigator), который позволяет буквально «ограбить» ваших конкурентов на предмет используемых ими ключевых слов (смотрите кейсы по увеличению продаж в eCommerce с помощью Серпстата). Есть и другие подобные «грабящие конкурентов» сервисы (spywords, keys.so), но я «прикипел» именно к бывшему Продвигатору.
В конце концов, есть и бесплатный Букварис, который позволяет очень быстро стартануть в сборе запросов. Также можно заказать частным образом выгрузку из монстрообразной базы Ahrefs и получить опять таки ключи ваших конкурентов. Вообще, стоит рассматривать все, что может принести хотя бы толику полезных для будущего продвижения запросов, которые потом не так уж сложно будет почистить и объединить в один большой (зачастую даже огромный список).
Все это мы (в общих чертах, конечно же) рассмотрим чуть ниже, но в конце всегда встает главный вопрос — что делать дальше. На самом деле, страшно бывает даже просто подступиться к тому, что мы получили в результате (пограбив десяток-другой конкурентов и поскребя по сусекам Кейколлектором). Голова может лопнуть от попытки разбить все эти запросы (ключевые слова) по отдельным страницах будущего или уже существующего сайта.
Какие запросы будут удачно уживаться на одной странице, а какие даже не стоит пытаться объединять? Реально сложный вопрос, который я ранее решал чисто интуитивно, ибо анализировать выдачу Яндекса (или Гугла) на предмет «а как там у конкурентов» вручную убого, а варианты автоматизации под руку не попадались. Ну, до поры до времени. Все ж таки подобный инструмент «всплыл» и о нем сегодня пойдет речь в заключительной части статьи.
Это не онлайн-сервис, а программное решение, дистрибутив которого можно скачать на главной странице официального сайта (демо-версию).
Посему никаких ограничений на количество обрабатываемых запросов нет — сколько надо, столько и обрабатывайте (есть, однако, нюансы в сборе данных). Платная версия стоит менее двух тысяч, что для решаемых задач, можно сказать, даром (имхо).
Но про техническую сторону KeyAssort мы чуть ниже поговорим, а тут хотелось бы сказать про сам принцип, который позволяет разбить список ключевых слов (практически любой длины) на кластеры, т.е. набор ключевых слов, которые с успехом можно использовать на одной странице сайта (оптимизировать под них текст, заголовки и ссылочную массу — применить магию SEO).
Откуда вообще можно черпать информацию? Кто подскажет, что «выгорит», а что достоверно не сработает? Очевидно, что лучшим советчиком будет сама поисковая система (в нашем случае Яндекс, как кладезь коммерческих запросов). Достаточно посмотреть на большом объеме данных выдачу (допустим, проаналазировать ТОП 10) по всем этим запросам (из собранного списка будущего семядра) и понять, что удалось вашим конкурентам успешно объединить на одной странице. Если эта тенденция будет несколько раз повторяться, то можно говорить о закономерности, а на основе нее уже можно бить ключи на кластеры.
KeyAssort позволяет в настройках задавать «строгость», с которой будут формироваться кластеры (отбирать ключи, которые можно использовать на одной странице). Например, для коммерции имеет смысл ужесточать требования отбора, ибо важно получить гарантированный результат, пусть и за счет чуть больших затрат на написание текстов под большее число кластеров. Для информационных сайтов можно наоборот сделать некоторые послабления, чтобы меньшими усилиями получить потенциально больший трафик (с несколько большим риском «невыгорания»). Как это сделать опять же поговорим.
А что делать, если у вас уже есть сайт с кучей статей, но вы хотите расширить существующее семядро и оптимизировать уже имеющиеся статьи под большее число ключей, чтобы за минимум усилий (чуток сместить акцент ключей) получить поболе трафика? Эта программка и на этот вопрос дает ответ — можно те запросы, под которые уже оптимизированы существующие страницы, сделать маркерными, и вокруг них KeyAssort соберет кластер с дополнительными запросами, которые вполне успешно продвигают (на одной странице) ваши конкуренты по выдаче. Интересненько так получается…
Как собрать пул запросов по нужной вам тематике?
Любое семантическое ядро начинается, по сути, со сбора огромного количества запросов, большая часть из которых будет отброшена. Но главное, чтобы на первичном этапе в него попали те самые «жемчужины», под которые потом и будут создаваться и продвигаться отдельные страницы вашего будущего или уже существующего сайта. На данном этапе, наверное, самым важным является набрать как можно больше более-менее подходящих запросов и ничего не упустить, а пустышки потом легко отсеяться.
Встает справедливый вопрос, а какие инструменты для этого использовать? Есть один однозначный и очень правильный ответ — разные. Чем больше, тем лучше. Однако, эти самые методики сбора семантического ядра, наверное, стоит перечислить и дать общие оценки и рекомендации по их использованию.
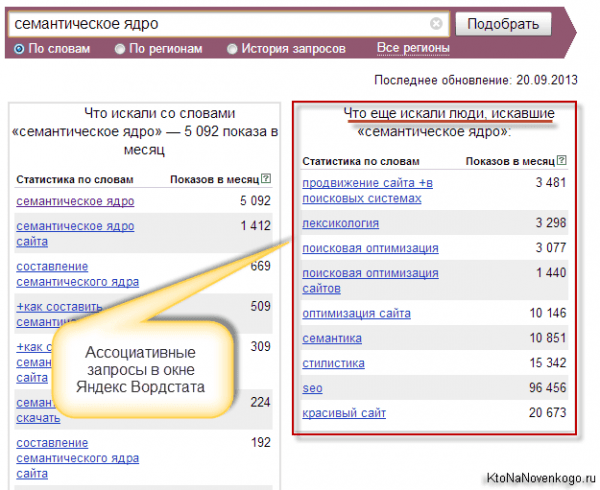
Из недостатков Водстата можно отметить:
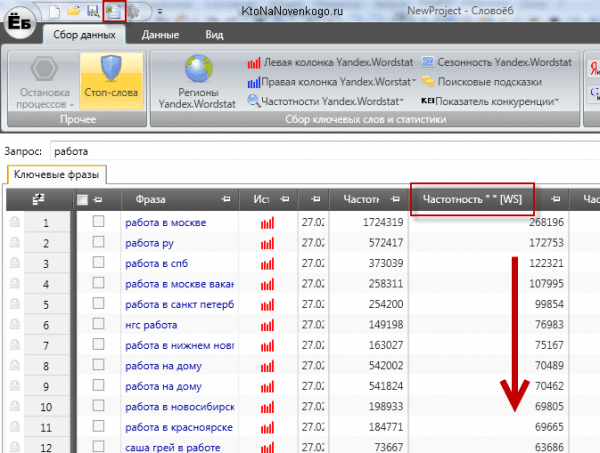
Подробности можете почитать в статье «Автоматизация сбора семядра в Slovoeb». Обе программы помогут вам собрать запросы и из правой, и из левой колонки Вордстата, а также поисковые подсказки по нужным вам ключевым фразам. Подсказки — это то, что выпадает из поисковой строки, когда вы начинаете набирать запрос. Пользователи часто не закончив набор просто выбирают наиболее подходящий из этого списка вариант. Сеошники это дело просекли и используют такие запросы в оптимизации и даже пытаются их накручивать.
КК и SE позволяют сразу набрать очень большой пул запросов (правда, может потребоваться много времени, либо покупка XML лимитов, но об этом чуть ниже) и легко отсеять пустышки, например, проверкой частотности фраз взятых в кавычки (учите матчасть, если не поняли о чем речь — ссылки в начале публикации) или задав список стоп-слов (особо актуально для коммерции). После чего весь пул запросов можно легко экспортировать в Эксель для дальнейшей работы или для загрузки в KeyAssort (кластеризатор), о котором речь пойдет ниже.
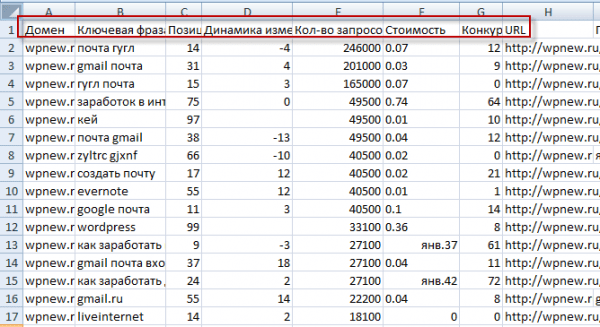
Не так давно я пользовал почти самый дорогой тарифный план Серпстата (но только один месяц) и успел за это время насохранять в Экселе чуть ли не гигабайт разных полезняшек. Собрал не только ключи конкурентов, но и просто пулы запросов по интересовавшим меня ключевым фразам, а также собрал семядра самых удачных страниц своих конкурентов, что, мне кажется, тоже очень важно. Одно плохо — теперь никак время не найду, чтобы вплотную заняться обработкой всей это бесценной информации. Но возможно, что KeyAssort все-таки снимет оцепенение перед чудовищной махиной данных, которые нужно обработать.
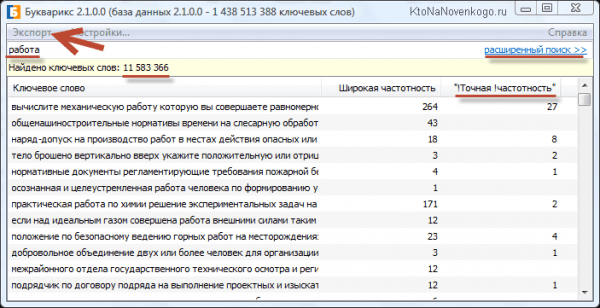
Но не только скорость сбора семядра является основным плюсом по сравнению с Вордстатом и КейКоллектором. Главное, что тут нет ограничений на 2000 строк для каждого запроса, а значит никакие НЧ и сверх НЧ от нас не ускользнут. Конечно же, частотность можно будет еще раз уточнить через тот же КК и по стоп-словам в нем отсев провести, но основную задачу Букварикс выполняет замечательно. Правда, сортировка по столбцам у него не работает, но сохранив пул запросов в Эксель там можно будет сортировать как заблагороссудится.
Наверное, еще как минимум несколько «серьезных» инструментов собора пула запросов приведете вы сами в комментариях, а я их успешно позаимствую…
Как очистить собранные поисковые запросы от «пустышек» и «мусора»?
Полученный в результате описанных выше манипуляций список, скорее всего, будет весьма большим (если не огромным). Поэтому прежде чем загружать его в кластерезатор (у нас это будет KeyAssort) имеет смысл его слегка почистить. Для этого пул запросов, например, можно выгрузить к кейколлектор и убрать:
Скажите, что это слишком просто на словах, но сложно на деле. А вот и нет. Почему? А потому что один уважаемый мною человек (Михаил Шакин) не пожалел времени и записал видео с подробным описанием способов очистки поисковых запросов в Key Collector:
Спасибо ему за это, ибо данные вопрос гораздо проще и понятнее показать, чем описать в статье. В общем справитесь, ибо я в вас верю…
Настройка кластеризатора семядра KeyAssort под ваш сайт
Собственно, начинается самое интересное. Теперь весь этот огромный список ключей нужно будет как-то разбить (раскидать) на отдельных страницах вашего будущего или уже существующего сайта (который вы хотите существенно улучшить в плане приносимого с поисковых систем трафика). Не буду повторяться и говорить о принципах и сложности данного процесса, ибо зачем тогда я первую часть этой стать писал.
Итак, наш метод довольно прост. Идем на официальный сайт KeyAssort и скачиваем демо-версию, чтобы попробовать программу на зуб (отличие демо от полной версии — это невозможность выгрузить, то бишь экспортировать собранное семядро), а уже опосля можно будет и оплатить (1900 рубликов — мало, мало по современным реалиям). Если хотите сразу начать работу над ядром что называется «на чистовик», то лучше тогда выбрать полную версию с возможностью экспорта.
Программа КейАссорт сама собирать ключи не умеет (это, собственно, и не ее прерогатива), а посему их потребуется в нее загрузить. Сделать это можно четырьмя способами — вручную (наверное, имеется смысл прибегать к этому методу для добавления каких-то найденных уже опосля основного сбора ключей), а также три пакетных способа импорта ключей:
Да, что я вам рассказываю — лучше один раз увидеть:
В любом случае, сначала не забудьте создать новый проект в том же самом меню «Файл», а уже потом только станет доступной функция импорта:
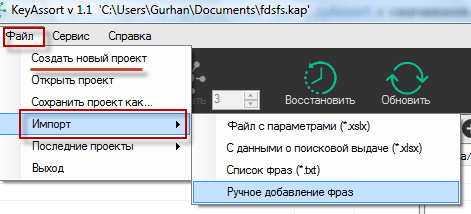
Давайте пробежимся по настройкам программы (благо их совсем немного), ибо для разных типов сайтов может оказаться оптимальным разный набор настроек. Открываете вкладку «Сервис» — «Настройки программы» и можно сразу переходить на вкладку «Кластеризация»:
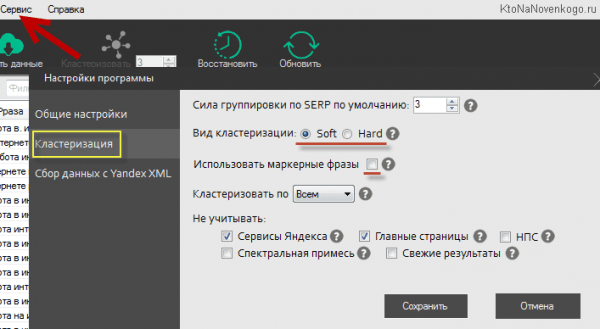
Тут самое важное — это, пожалуй, выбор необходимого вам вида кластеризации. В программе могут использоваться два принципа, по которым запросы объединяются в группы (кластеры) — жесткий и мягкий.
Есть хорошая картинка наглядно все это иллюстрирующая:
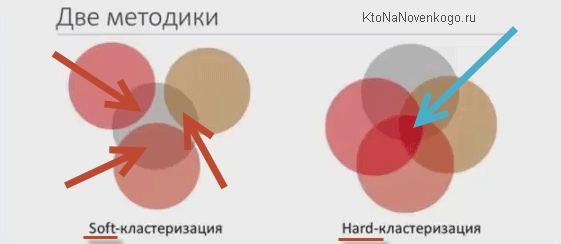
Если непонятно, то не берите в голову, ибо это просто объяснение принципа, а нам важна не теория, а практика, которая гласит, что:
Еще одной важной, на мой взгляд, настройкой является галочка в поле «Использовать маркерные фразы». Зачем это может понадобиться? Давайте посмотрим.
Допустим, что у вас уже есть сайт, но страницы на нем были оптимизированы не под пул запросов, а под какой-то один, или же этот пул вы считаете недостаточно объемным. При этом вы всем сердцем хотите расширить семядро не только за счет добавления новых страниц, но и за счет совершенствования уже существующих (это все же проще в плане реализации). Значит нужно для каждой такой страниц добрать семядро «до полного».
Именно для этого и нужна эта настройка. После ее активации напротив каждой фразы в вашем списке запросов можно будет поставить галочку. Вам останется только отыскать те основные запросы, под которые вы уже оптимизировали существующие страницы своего сайта (по одному на страницу) и программа KeyAssort выстроит кластеры именно вокруг них. Собственно, все. Подробнее в этом видео:
Еще одна важная (для правильной работы программы) настройка живет на вкладке «Сбор данных с Яндекс XML». Что такое Яндекс XML и что такое лимиты вы можете прочитать в приведенной статье. Если вкратце, то Сеошники постоянно парсят выдачу Яндекса и выдачу Вордстата, создавая чрезмерную нагрузку на его мощности. Для защиты была внедрена капча, а также разработан спецдоступ по XML, где уже не будет вылезать капча и не будет происходить искажение данных по проверяемым ключам. Правда, число таких проверок в сутки будет строго ограничено.
От чего зависит число выделенных лимитов? От того, как Яндекс оценит ваши сайты добавленные в панель Вебмастера. Посмотреть лимиты можно перейдя по этой ссылке (находясь в том же браузере, где вы авторизованы в Я.Вебмастере). Например, у меня это выглядит так:
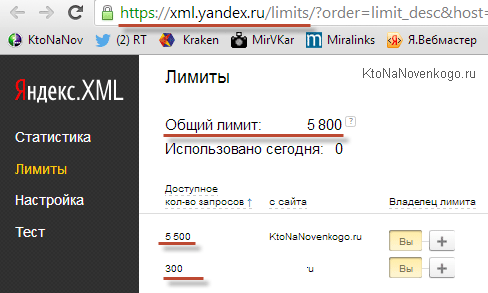
Там еще есть снизу график распределения лимитов по времени суток, что тоже важно. Если запросов нужно пробить много, а лимитов мало, то не проблема. Их можно докупить. Не у Яндекса, конечно же, напрямую, а у тех, у кого эти лимиты есть, но они им не нужны.
Механизм Яндекс XML позволяет проводить передачу лимитов, а биржи, подвязавшиеся быть посредниками, помогают все это автоматизировать. Например, на XMLProxy можно прикупить лимитов всего лишь по 5 рублей за 1000 запросов, что, согласитесь, совсем уж не дорого.
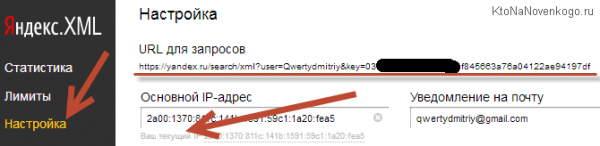
Но не суть важно, ибо купленные вами лимиты все равно ведь перетекут к вам на «счет», а вот чтобы их использовать в KeyAssort, нужно будет перейти на вкладку «Настройка» и скопировать длинную ссылку в поле «URL для запросов» (не забудьте кликнуть по «Ваш текущий IP» и нажать на кнопку «Сохранить», чтобы привязать ключ к вашему компу):
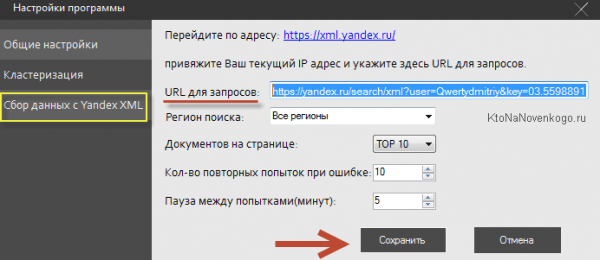
После чего останется только вставить этот Урл в окно с настройками KeyAssort в поле «Урл для запросов»:
Собственно все, с настройками KeyAssort покончено — можно приступать к кластеризации семантического ядра.
Кластеризация ключевых фраз в KeyAssort
Итак, надеюсь, что вы все настроили (выбрали нужный тип кластеризации, подключили свои или покупные лимиты от Яндекс XML), разобрались со способами импорта списка с запросами, ну и успешно все это дело перенесли в КейАссорт. Что дальше? А дальше уж точно самое интересное — запуск сбора данных (Урлов сайтов из Топ10 по каждому запросу) и последующая кластеризация всего списка на основе этих данных и сделанных вами настроек.
Итак, для начала жмем на кнопку «Собрать данные» и ожидаем от нескольких минут до нескольких часов, пока программа прошерстит Топы по всем запросам из списка (чем их больше, тем дольше ждать):
У меня на три сотни запросов (это маленькое ядро для серии статей про работу в интернете) ушло около минуты. После чего можно уже приступать непосредственно к кластеризации, становится доступна одноименная кнопка на панели инструментов KeyAssort. Процесс этот очень быстрый, и буквально через несколько секунд я получил целый набор калстеров (групп), оформленных в виде вложенных списков:
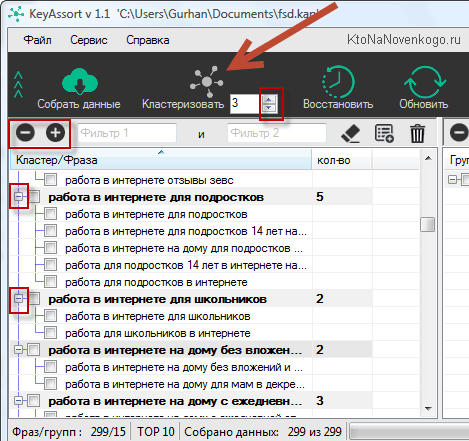
Подробнее об использовании интерфейса программы, а также про создание кластеров для уже существующих страниц сайта смотрите лучше в ролике, ибо так гораздо нагляднее:
Все, что хотели, то мы и получили, и заметьте — на полном автомате. Лепота.
Хотя, если вы создаете новый сайт, то кроме кластеризации очень важно бывает наметить будущую структуру сайта (определить разделы/категории и распределить по ним кластеры для будущих страниц). Как ни странно, но это вполне удобно делать именно в KeyAssort, но правда уже не в автоматическом режиме, а в ручном режиме. Как?
Проще опять же будет один раз увидеть — все верстается буквально на глазах простым перетаскиванием кластеров из левого окна программы в правое:
Если программу вы таки купили, то сможете экспортировать полученное семантическое ядро (а фактически структуру будущего сайта) в Эксель. Причем, на первой вкладке с запросами можно будет работать в виде единого списка, а на второй уже будет сохранена та структура, что вы настроили в KeyAssort. Весьма, весьма удобно.
Ну, как бы все. Готов обсудить и услышать ваше мнение по поводу сбора семядра для сайта.
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Источник: ktonanovenkogo.ru







